
La classe vector nella libreria di C++
La classe vector permette di creare un vettore dinamico e di gestire gli elementi che lo compongono. #include<vector> Per dichiarare un vettore che faccia uso della libreria vector si deve scrivere la seguente istruzione: vector<int>a; se si vuole definire la sua dimensione iniziale ad esempio 4 elementi: vector<int>a(4); se si…
Continua a leggere
Enoteca online (applicazione)
Acquisti vini italiani Puoi entrare come ospite digitando guest nella casella di username!!! Username Password
Continua a leggere
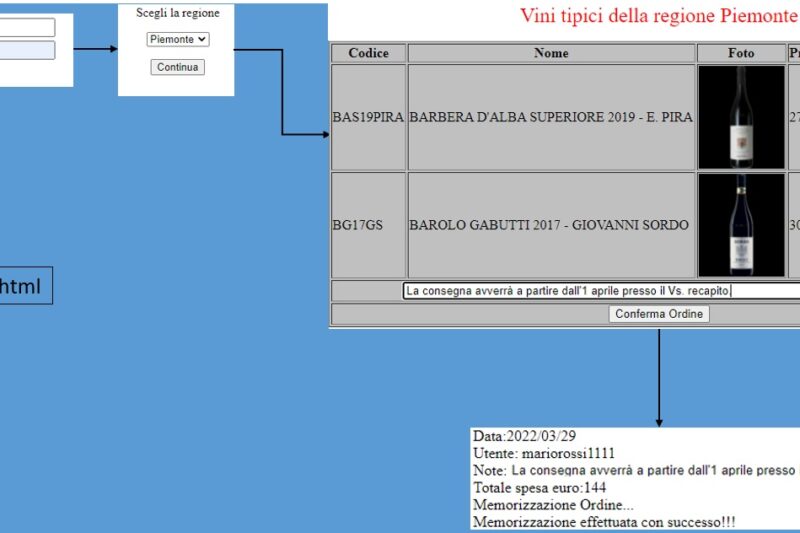
Progettazione Enoteca Online
Progettare sito web per gli acquisti online di vini prodotti in Italia. Mediante un’interrogazione ad una base di dati viene estratto l’elenco delle regioni che hanno vini nel catalogo. Selezionata una regione, viene visualizzato l’elenco dei suoi vini, con una breve descrizione, l’immagine della bottiglia e il relativo prezzo di…
Continua a leggere
Installazione MongoDB su Windows 10
Dal sito: https://www.mongodb.com/try/download/enterprise, e in particolare alla finestra posta sulla destra della pagina, selezionare la versione (attualmente è la 4.4.5), la piattaforma sulla quale installare il database MongoDB (valore di default: Windows) e il tipo di pacchetto (valore di default: msi). Cliccare su Download. . Il file scaricato è mongodb-windows-x86_64-enterprise-4.4.5-signed.msi.…
Continua a leggere
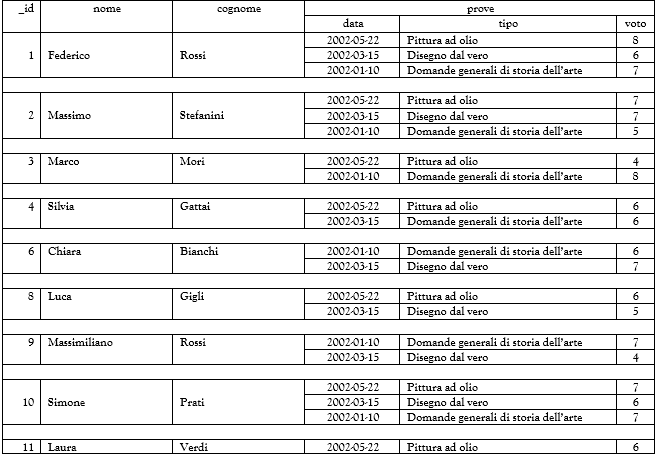
Esercitazione
Consideriamo la collection esiti con i seguenti documenti: Progettare un database denominato arte non relazionale a documenti (mongodb). La collection esiti ha come sub-collection prove (relazione 1 a molti tra esiti e prove).
Continua a leggere
Modellazione dei dati
Quando si utilizza MongoDB, o in generale la maggioranza dei database NoSQL, la modellazione dei dati è una fase molto delicata dello sviluppo di una soluzione software. Infatti, a differenza di database relazionali, per cui esiste una vasta letteratura e molti strumenti software per la modellazione dei dati, qui esistono…
Continua a leggere
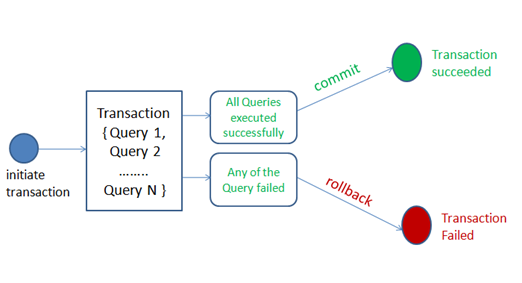
MySQL vs. MongoDB
Si supponga di avere il database relazionale BLOG costituito dalle tabelle AUTORI, ARTICOLI, COMMENTI e CATEGORIE. Definiamo le seguenti relazioni: AUTORI -> ARTICOLI (1 a molti) Un autore può scrivere più articolo, ma un articolo è scritto da un solo autore ARTICOLI -> COMMENTI (1 a molti)…
Continua a leggere
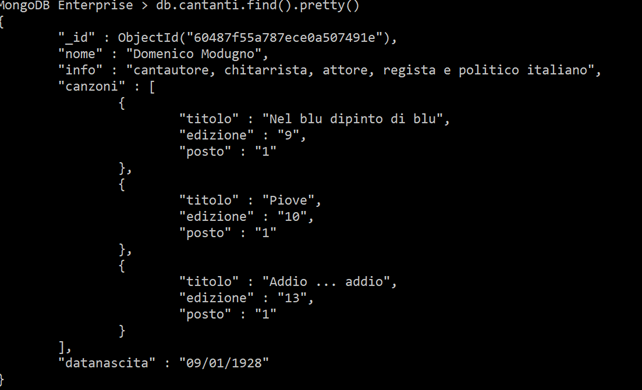
Esempio di applicazione
Supponiamo che il database relazionale sia costituito dalle seguenti tabelle con i relativi attributi e relazione. Schema relazionale del database SANREMO Cantanti (nome, info) Canzoni (titolo, edizione, posto, nomecantante) Supponiamo inoltre che la tabella Cantanti contenga le seguenti informazioni: nome info Domenico Modugno cantautore, chitarrista, attore, regista e politico italiano…
Continua a leggere
Breviario di MongoDB per Windows
Questo breviario base vuol essere un primo approccio didattico all’utilizzo del database NoSQL orientato a documenti (documents-oriented). Dopo aver installato mongoDB sul proprio PC e aver creato una cartella in cui inserire il database ad esempio in una cartella sul desktop denominato db_mongo, si accede al prompt e alla richiesta…
Continua a leggere

La programmazione orientata agli oggetti
Object Oriented Programming La programmazione orientata agli oggetti (OOP, Object Oriented Programming) è un paradigma di programmazione che prevede di raggruppare in un’unica entità (la classe descrizione astratta di un tipo di dato) sia le strutture dati che le procedure che operano su di esse, creando un oggetto (istanza della classe) software…
Continua a leggere
PHP Code Snippets Powered By : XYZScripts.com
Tema Seamless Just Pretty, sviluppato da Altervista
Apri un sito e guadagna con Altervista - Disclaimer - Segnala abuso - Privacy Policy - Personalizza tracciamento pubblicitario